Tutorial
A bot or a spider crawls your site to index the pages and update their search engines. The most common bot is the GoogleBot which is Google's web crawling bot (sometimes also called a "spider"). Crawling is the process by which Googlebot discovers new and updated pages to be added to the Google index.
The Robots Exclusion Protocol or "Robots.txt" is the universal way of giving instructions to these bots. Customizing that file allows you to prevent bots from indexing specific pages or areas of your site.
Your robots.txt file can be seen by visiting this link on your site:
https://www.yoursite.com/robots.txt
The robots.txt file can be updated through your control panel to allow you to quickly and easily set which areas allow the GoogleBot and other Bots to access or disallow access.
Manage the bots that visit your site
Here's how to quickly and easily manage the bots that come to your Membergate site
Click on each section to expand for more information:
The management of the Robots.txt file can be found under Utilities Robots.txt
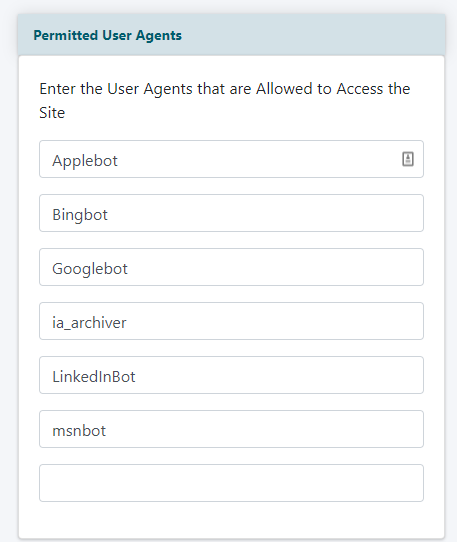
Permitted User Agents
In the 'Permitted User Agents' field add specific bot names that are allowed to crawl and access your pages to add to their search engine index.
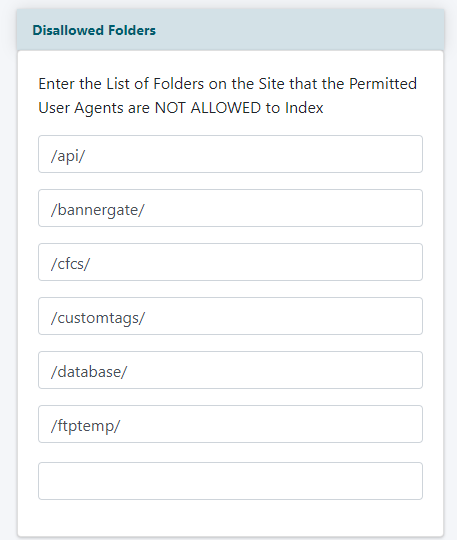
Disallowed Folders
Add directory or folder paths that you would like to prevent bots from crawling.
Remember to include the / (backslash) in front of each folder and in between each subdirectory.
For example, the images folder inside the members folder would be entered like this:
/members/images
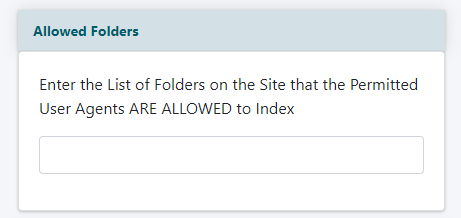
Allowed Folders
Add a specific directory or folder paths that are okay for bots to crawl . The robots.txt file is usually defaulted to allow a bot to crawl all of your folders (except some specific folders necessary for some software functions)
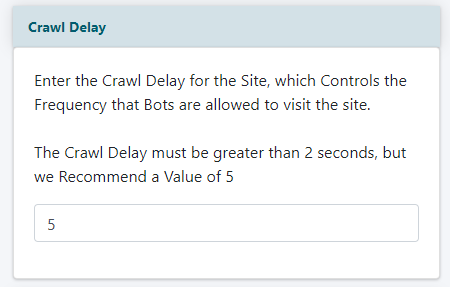
Crawl Delay
Add a number in seconds that controls the frequency to which bots can visit your site. We suggest 5, but the number has to be greater than 2
Default Bot Action
Select Allow or Disallow from the drop down menu. This is the permission for bots not listed in the 'Permitted User Agents'. We recommend having this set as 'disallow'
Click the button at the bottom of the page.